One of my favorite things to do on the Moog One (and Prophet 12) is to take a preset on Synth Layer 1, copy it to Synth Layer 2, and then make slight changes to the second layer (OSC shapes, Filter envelopes, Filter Cutoffs, LFO speeds and modulation amounts), and then pan the 2 layers hard left and hard right. The multiple small/minute differences between the two sides of the stereo field create such a lush and gorgeous sound.
This is how I create nearly every patch now, including monophonic patches. But there's one terrible drawback with it: once you've heard this sort of broad stereo richness, you can never go back. After such an experience, a mono-signal synthesizer sounds sterile and lifeless.
Yeah... it's addictive. And that's one of the reasons why I truly enjoy the Prophet X -- it's stereo filters get you most of the way there.
I'm imagining a truly stereo synth (mono or poly) where every parameter (OSC shapes, filter cutoffs, filter resonances, all envelope stages, all LFO parameters, all modulation amounts) could have an adjustable offset between the left and right side of the stereo path. I already do this, as stated, on the Moog One and Prophet 12, but having this power available on 1 layer from the front panel... 
Definitely agree that the stereo binarual is addicting! Basically creating a double tracked stereo synth sound in one pass, real time. About half of the patches in the VCM patch bank I did for Rev2 incorporate this type of sound design with stacked, hard panned layers. With a good stereo monitor setup, or headphones, they just sound so immense, and when you go back to a mono (or regular stereo) type of patch, they just sound so much more 1-dimensional... Minus bass sound designs and some specific famous/classic patch recreations, I use this technique extensively.
The Rev2 is quite capable of doing all what you said, Shaw... stacked/hard panned stereo layers, with per voice, per component offsets to osc tuning, env timing, filter cutoff, resonance, etc. On some patches, I've even got complex macro type behaviors on a per voice, stereo basis (osc glitches like you would find in old MemoryMoogs, osc tuning settle in the transient attack phase, per voice... etc) It requires a bit of setup, but once you know how to do it, its actually fairly quick. I generally do the main sound design, add in voice modeling offsets (2-4 minutes once you know how), then copy/paste/stack the patch, then do a little fine tuning to layer B to add a bit more per voice variance. This video shows my typical sound design process for this:
https://youtu.be/jB9HG3k3vvQ?t=352It's not automated, but like I said, once you do it a couple times and understand the value scaling and offsets, it only takes a few minutes to integrate deep, stereo voice modeling into the Rev2... It's also super customizable - you can target virtually any component for voice variance, including macro type behaviors, and you can even define "virtual voice counts" (ie: 5, 6, 8 virtual voices that have repeating patterns of imperfection)
My hope is that the next flagship synth from Seq will be a PolyEvolver 12 or 16, or a Prophet08 Rev3 - with bi/tri-timbral, two or three routable filters, mod transforms, and deep voice modeling implementation like outlined at the bottom of the VCM article:
http://www.VoiceComponentModeling.com - Hoping next year we'll see something like this - that would be my dream synth.
Example from my VCM site of potential future implementation (more details at the bottom of the VCM website):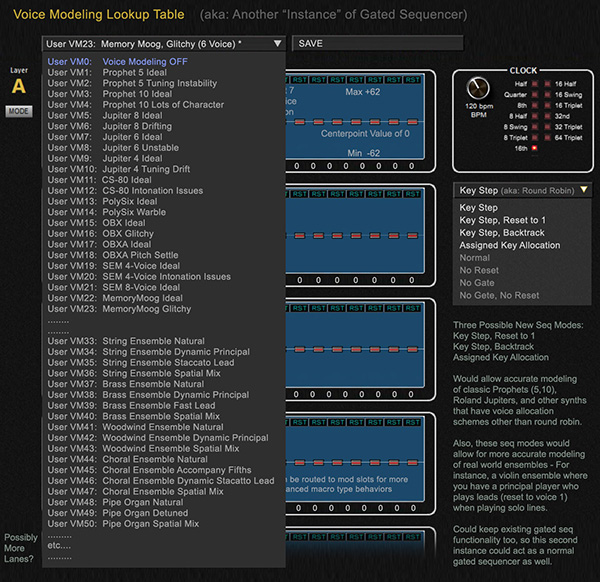
 290 Replies
290 Replies 75234 Views
75234 Views