I've been thinking about this a lot... I would keep the general model of the Gated Sequencer as a Voice Lookup Table: (over a more flat table of values to all defined attributes) Although, the idea of having a dedicated potentiometer/interface on the front of the synth to quickly toggle through saved voice templates would be totally awesome!
Reasons why keeping the gated sequencer / lookup table paradigm is good:
1. You've already got the majority of the programming infrastructure built for it, and its a perfect setup for voice modeling. The ideal solution may just be to create "another instance" of the gated sequencer lookup table, dedicated to voice modeling, with savable templates. You can copy a lot of existing IP / code blocks for the gated sequencer implementation, and just make adjustments/upgrades as you see fit.
2. The gated sequencer type of lookup table is VERY FLEXIBLE for voice modeling- Every type of classic synthesizer, or acoustic/analog ensemble that you are modeling will have different aspects to their voice-by-voice variations. It's important to be able to address each modeled instrument differently. ie: some will have large variance of osc tuning per voice, while others will have very little or none, or tuning may be based on intonation vs static voice based.
Some instruments may require more pronounced variance to attack/delay/release speeds, or only certain stages of envelope speeds. Some will require addressing totally different characteristics of VCO, VCF, VCA sections, while leaving other ones alone. Having ability to control each parameter independently is key if you really want to be able to capture the sound of specific classic synths, or ensembles of real world acoustic instrument sounds. It's not a one-size-fits-all type of scenario, and the gated sequencer / lookup table model allows you to more precisely model classic synths and real world ensembles.
3. Advanced macro-type controls for voice modeling: The gated sequencer paradigm for voice modeling also allows you to control more advanced behaviors on a voice-by-voice basis. For instance, you might build a macro type behavior that uses a note number modulator, routed to Env 3 amount, and the overall amount of note number is controlled by a lane in the gated sequencer, giving voice by voice variance to an "Oscillator Pitch Settle" type of behavior that requires multiple modulations. I have done this type of voice specific modeling in several patches I've built.
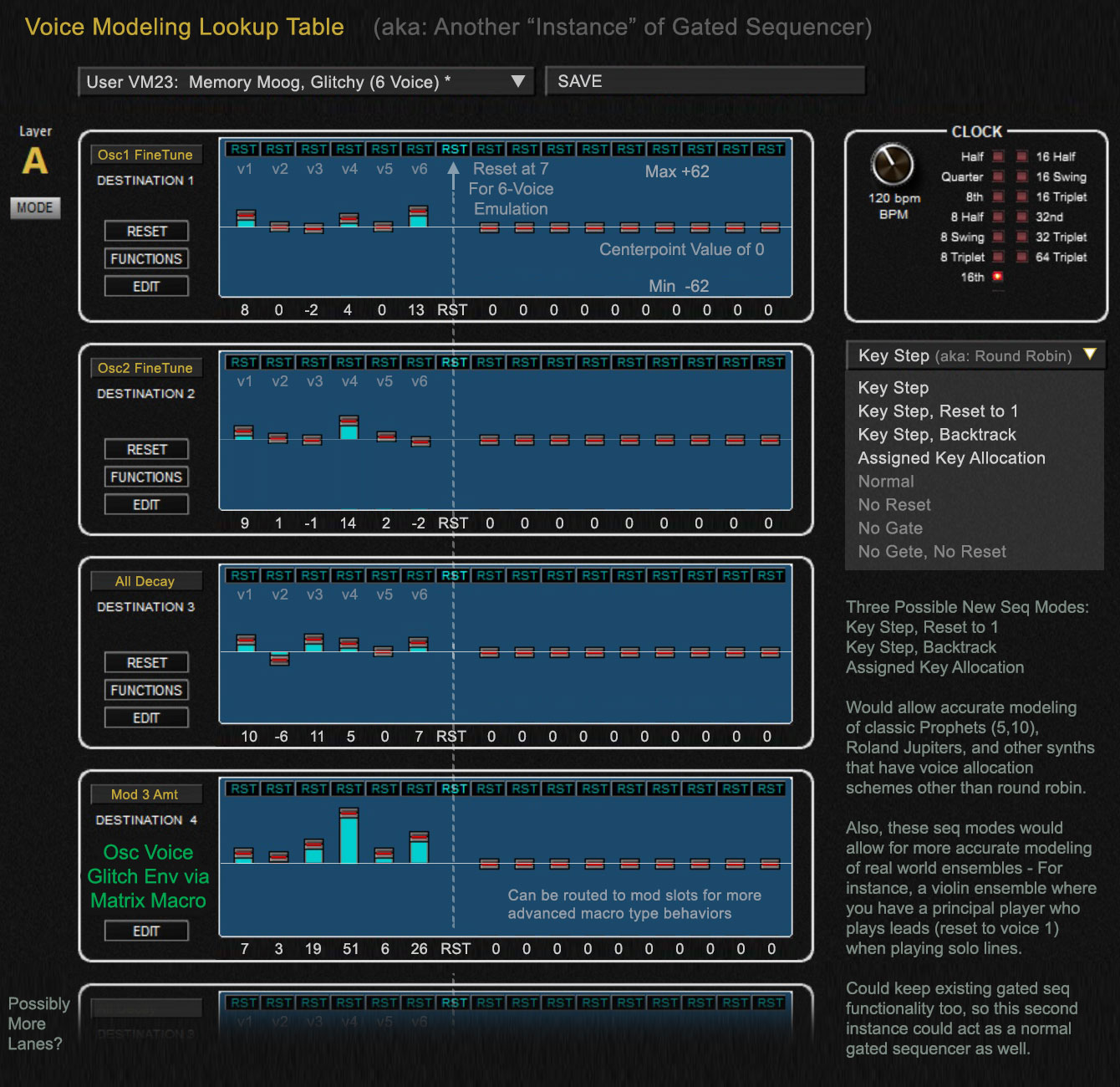
4. The Gated Sequencer lookup table model also allows you to define a virtual voice count within the synthesizer... by setting a reset at step 7, you can create a virtual six-voice synth, with repeating patterns of voice imperfection. This is very realistic if you wanted to model a classic synth from the past with a specific voice count that cycles. You can create any number of "virtual voices" in this manner, to replicate any synth from the past, or specific ensemble sizes for voice offsets.
Below, I've mocked up a hypothetical Voice Modeling table... most of the functionality has already been developed by you guys. The idea would be to just create "another instance" of the gated sequencer that is dedicated to allowing you to assign a voice model to a given patch... and adding some additional features to optimize it for voice-by-voice modeling.
a. change data range: use -62 to +62, instead of 0-125 ... works better to have 0 as a centerpoint with negative and positive offsets.
b. add a few new seq modes: (Key Step, Reset to 1), (Key Step, Backtrack), (Assigned Key Allocation) -- this will allow you to capture other voice allocation schemes besides round robin, so you can accurately model old Prophets, Jupiters or other synths that use different voice allocation schemes.. Also, this will allow for more accurate voice modeling of real world ensembles (string sections with a principal/lead player)
c. add the ability to save the voice modeling templates / presets... a hypothetical new board might ship with 64 factory defined voice models or something, but let users add their own user voice models if they want, or make adjustments and save them. Would allow players to easily take a preset, or Init patch, and select a voice model scheme and build a patch from it. If you had a dedicated knob like you were saying, you could quickly and easily scroll through voice models. Once you save a patch, it saves the voice model with the patch.
d. maybe add a couple more lanes (six or eight) for data. Note, even if this was not implemented as a separate instance of the gated sequencer, you could just build out the feature set on the gated seq, and add a couple extra lanes there.
Below are some visual mockups:Shown in the context of the Soundtower Editor style, as its a good visual representation of the capabilities of the gated sequencer paradigm.
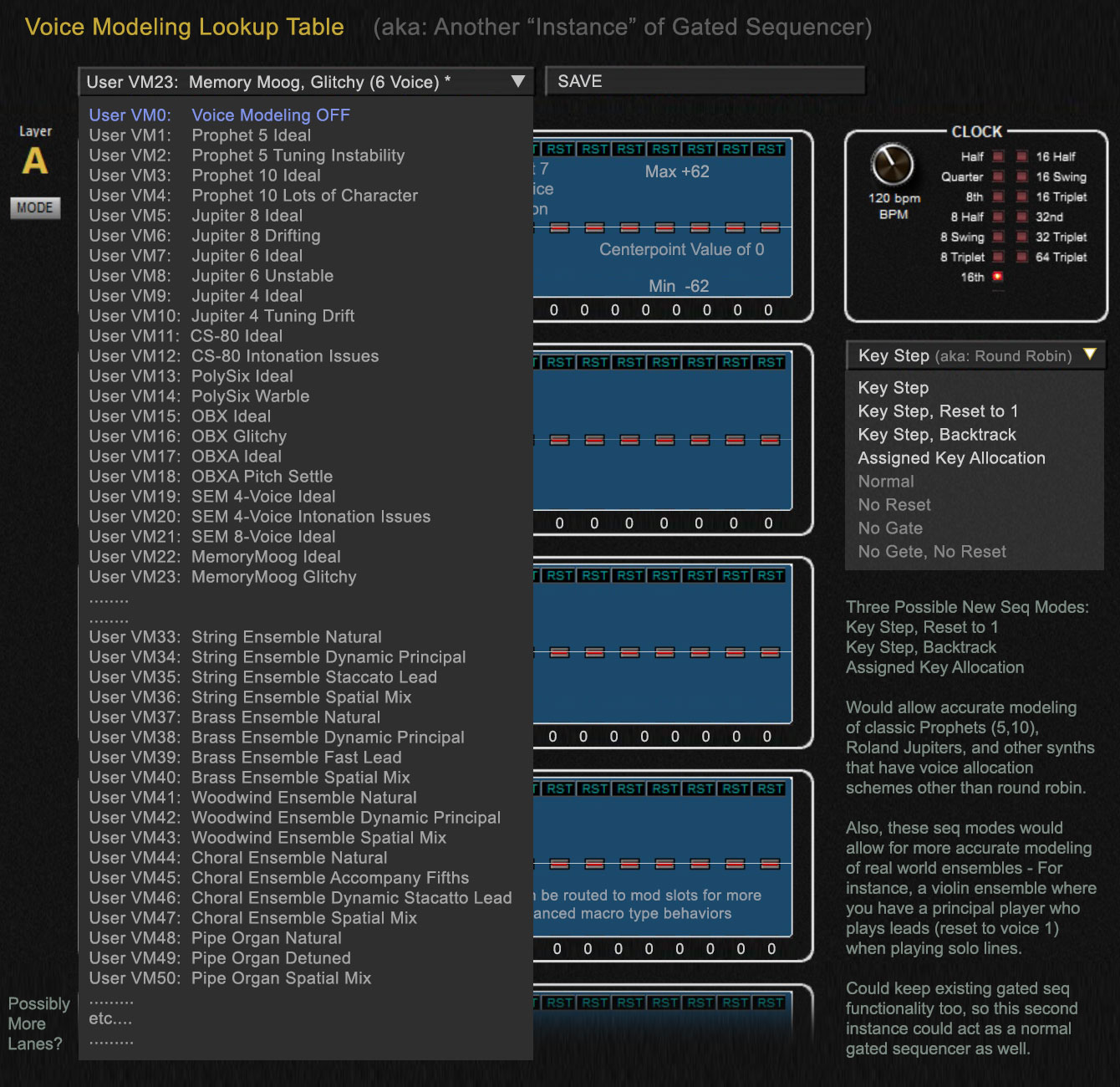
 Here's a mockup of opening a window of Saved Voice Model Templates:
Here's a mockup of opening a window of Saved Voice Model Templates:A potential future board might ship with 64 factory templates of various voice models for classic synths and acoustic ensemble types.
Also, added this to Section 5 of the VoiceComponentModeling.com website:
http://www.voicecomponentmodeling.combtw: thanks shiihs for the note about the site being down... was in process of changing servers.
 83 Replies
83 Replies 38719 Views
38719 Views